Outline
- Brief Artificial Neural Nerwork
- Brief Recurrent Neural Network
- Brief Long Short Term Memory (LSTM)
- Transformer
Brief Artificial Neural Network
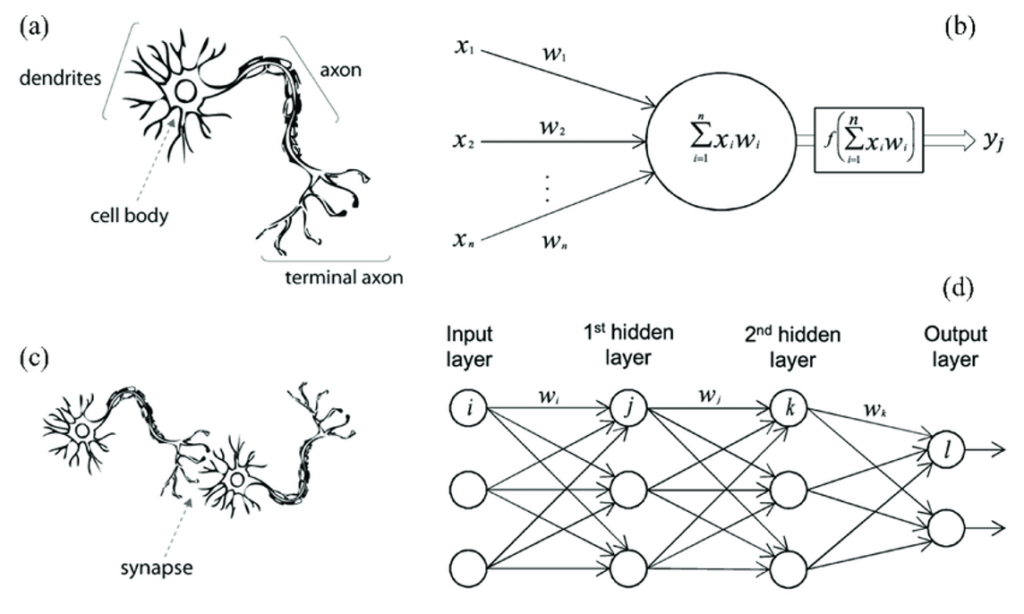
Gambar Analogi Artificial Neural Network (sumber)
Gambar Analogi Artificial Neural Network Sederhana (sumber, sumber sumber)
from numpy import exp, array, random, dot
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
random.seed(1)
synaptic_weights = 2 * random.random((3, 1)) - 1
for iteration in xrange(10000):
output = 1 / (1 + exp(-(dot(training_set_inputs, synaptic_weights))))
synaptic_weights += dot(training_set_inputs.T, (training_set_outputs - output) * output * (1 - output))
print 1 / (1 + exp(-(dot(array([1, 0, 0]), synaptic_weights))))import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)Brief Recurrent Neural Network
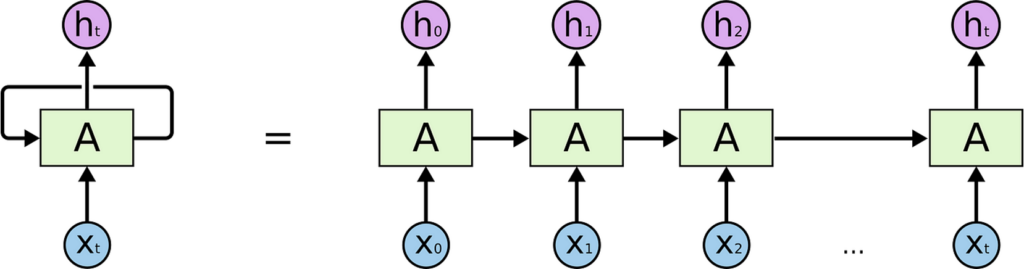
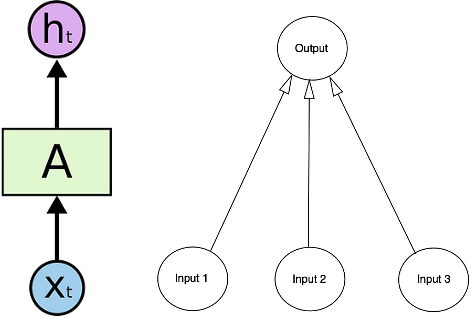
Gambar Arsitektur RNN (sumber)
import tensorflow as tf
model = keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.Dense(10))
model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)Brief Long Short Term Memory (LSTM)
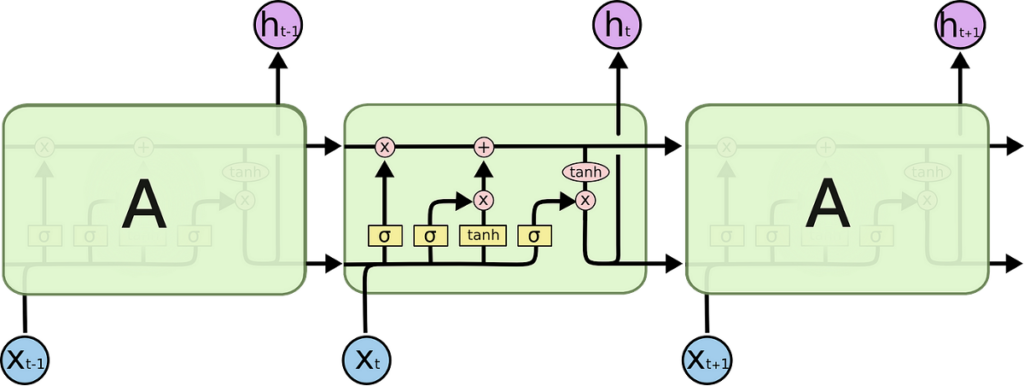
Gambar Arsitektur LSTM (sumber)
import tensorflow as tf
model = keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.LSTM(128))
model.add(layers.Dense(10))
model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)Transformer
Transformers can process language in parallel rather than sequentially, allowing them to handle vast amounts of data and capture complex relationships in language — all without losing track of long-range dependencies.
Transformer Task : Understanding, Machine Translation, Text Generation
Trasnformer Configuration : encoder-only, decoder-only, and encoder-decoder models
Encoder-Only Models (e.g., BERT)
- Encoder-only models are designed primarily for understanding and representation tasks, where generating new text isn’t required. These models excel at capturing intricate relationships within the text by learning high-quality embeddings of language data. Encoder-only models process input bidirectionally, allowing them to understand the context around each token by looking both forward and backward within a sentence.
- Strengths: Exceptional at language comprehension and representation learning. The bidirectional processing enables the model to discern complex relationships between words, providing a deeper understanding of context.
- Applications: Ideal for tasks that require analyzing or classifying text, such as:
- Sentence Classification: Determining the sentiment, topic, or intent of a sentence.
- Sentiment Analysis: Evaluating whether a piece of text expresses positive, negative, or neutral sentiments.
- Named Entity Recognition (NER): Identifying entities like people, organizations, and locations within the text.
- Question Answering: Finding relevant answers to questions based on text input.
- Real-World Example: BERT (Bidirectional Encoder Representations from Transformers) is widely used in search engines, helping improve relevance by analyzing the context of user queries to deliver more accurate results.
Decoder-Only Models (e.g., GPT Series)
- Decoder-only models, like the GPT (Generative Pre-trained Transformer) series, are optimized for generative tasks. Unlike encoder-only models, decoder-only architectures are unidirectional, processing tokens sequentially from left to right. This design is ideal for tasks that require predicting the next word or token in a sequence, ensuring that generated text is coherent and contextually appropriate.
- Strengths: Built specifically for text generation, these models excel at creating fluid, logical continuations of a prompt. They are particularly effective for tasks that need sequential prediction, which is key to producing natural, flowing language.
- Applications: Commonly used in tasks that require generating new text, such as:
- Conversational AI: Powering chatbots and virtual assistants with human-like dialogue.
- Creative Writing: Assisting in writing stories, poems, or other forms of creative content.
- Content Generation: Generating articles, social media posts, or summaries based on a brief or prompt.
- Code Generation: Converting natural language descriptions into executable code.
- Real-World Example: GPT models, like ChatGPT, are widely used in chatbots and virtual assistants to produce contextually relevant responses that align with the conversation history, delivering an engaging user experience.
Encoder-Decoder Models (e.g., T5)
- Encoder-decoder models combine both encoder and decoder stacks, making them exceptionally versatile. This architecture is designed for tasks where an input sequence needs to be transformed into a specific output sequence, such as translation, summarization, or paraphrasing. In these models, the encoder processes the input to create a rich representation, which is then passed to the decoder to generate the desired output.
- Strengths: Versatile and flexible, encoder-decoder models can handle a variety of tasks that require both understanding the input context and generating coherent output. This setup makes them robust for tasks that involve complex input-output mappings.
- Applications: Suitable for a range of NLP applications, including:
- Machine Translation: Translating text from one language to another (e.g., English to French).
- Text Summarization: Condensing lengthy articles or documents into shorter summaries.
- Text-to-Text Transformations: Tasks like rephrasing sentences, generating questions from statements, or filling in missing parts of a text.
- Real-World Example: T5 (Text-To-Text Transfer Transformer) is renowned for its ability to handle multiple NLP tasks within a single unified framework. By casting every problem as a text-to-text transformation, T5 can seamlessly switch between tasks, making it a versatile tool for diverse NLP applications.
How Transformer Work
- Tokenization and Embedding
- Adding Positional Encodings
- Self-Attention Computation
- Multi-Head Attention and Feed-Forward Networks (FFNs)
- Stacking Layers
- Output Generation
Architecture

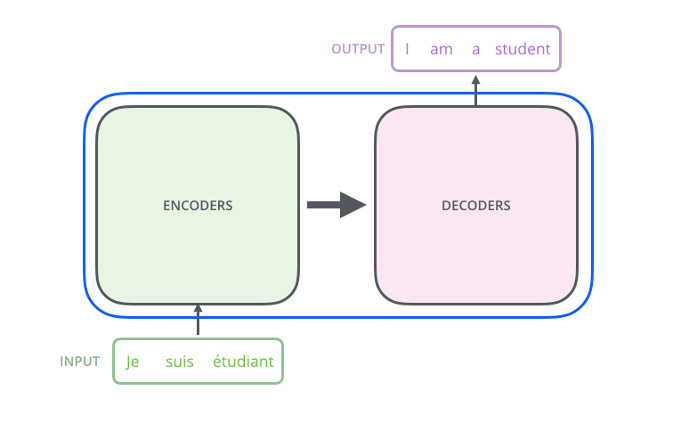
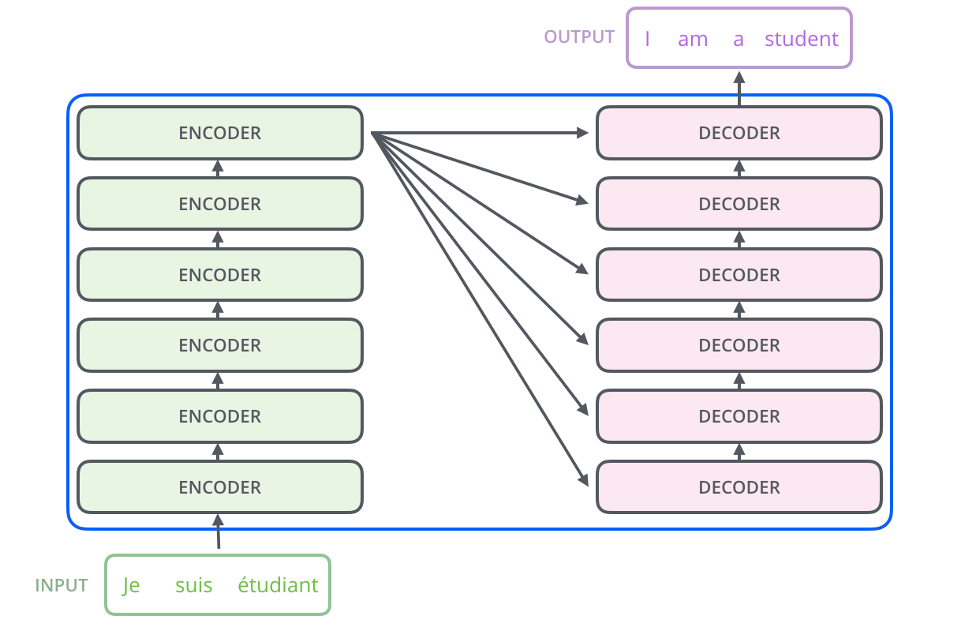
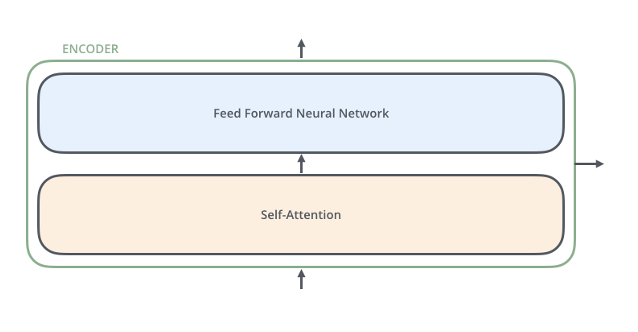
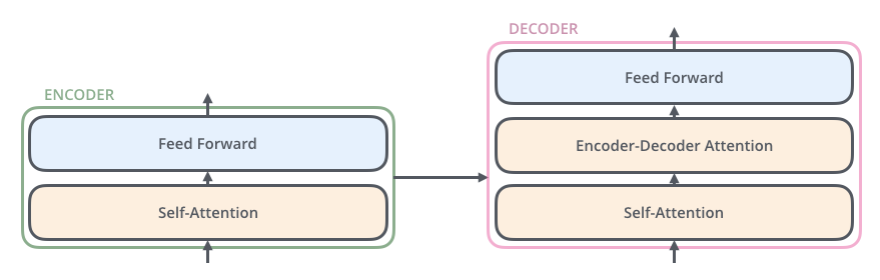
Embedding
Each word is embedded into a vector of size 512. We’ll represent those vectors with these simple boxes.

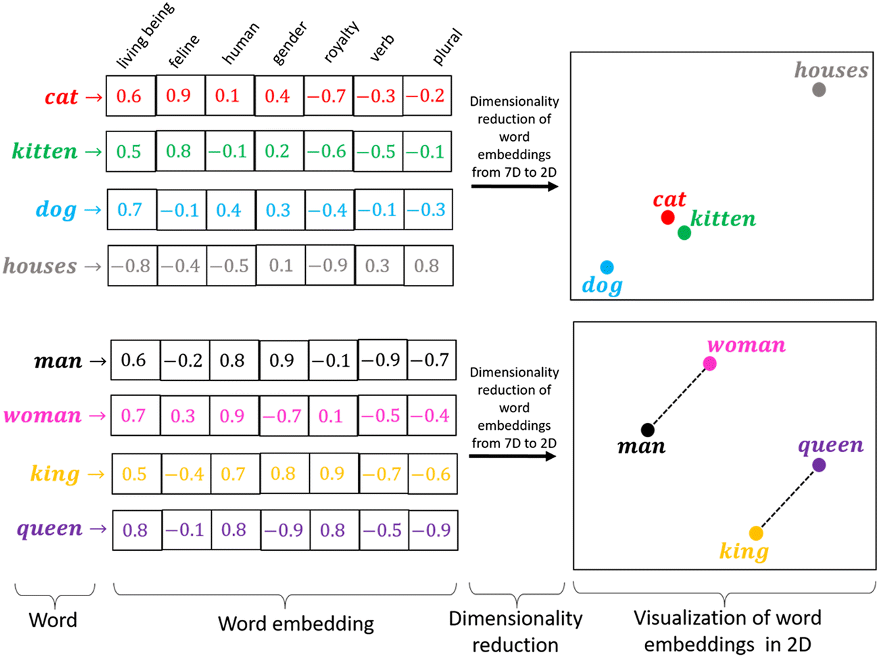
Ilustrasi Embedding (sumber)
Architecture
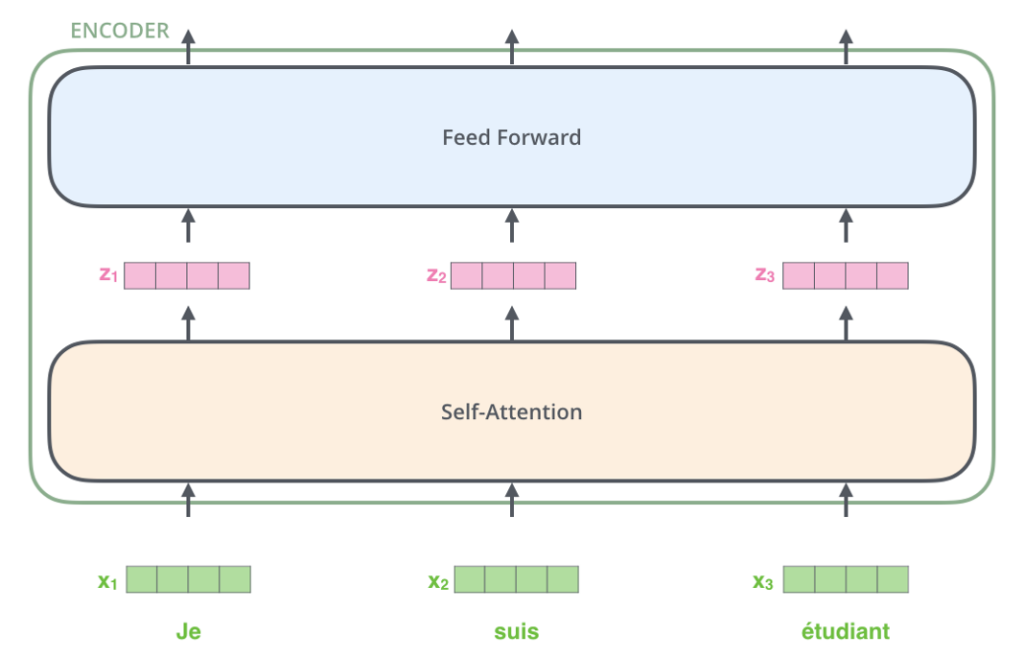
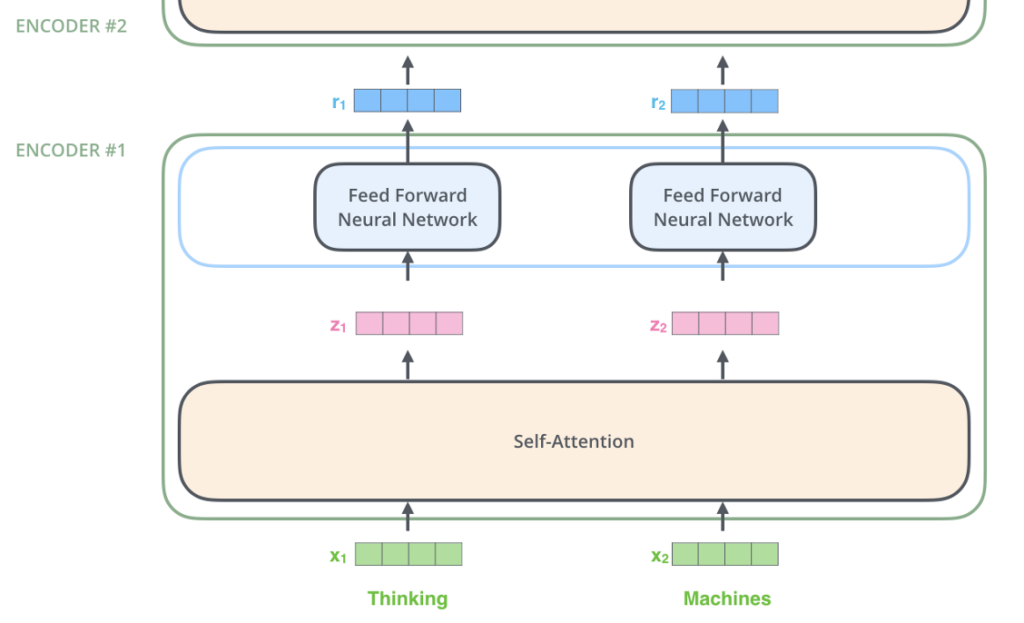
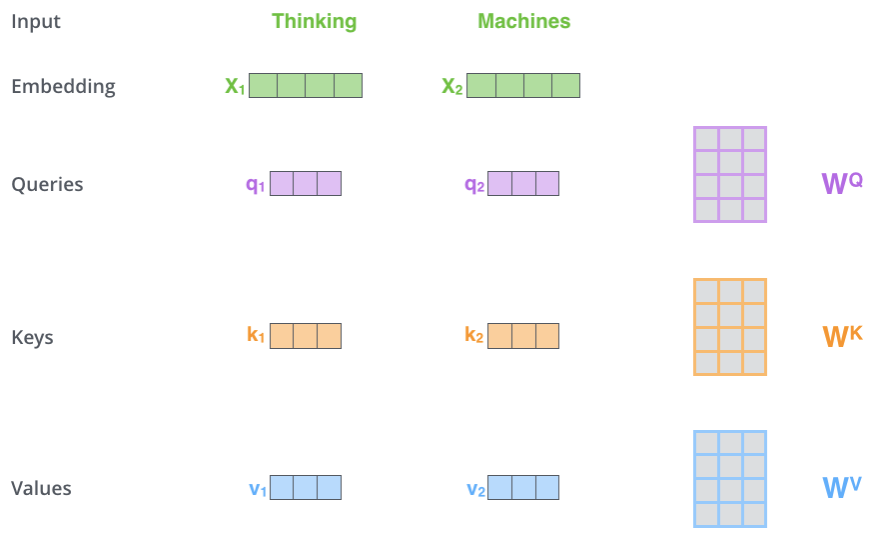
Architecture – Self Attention
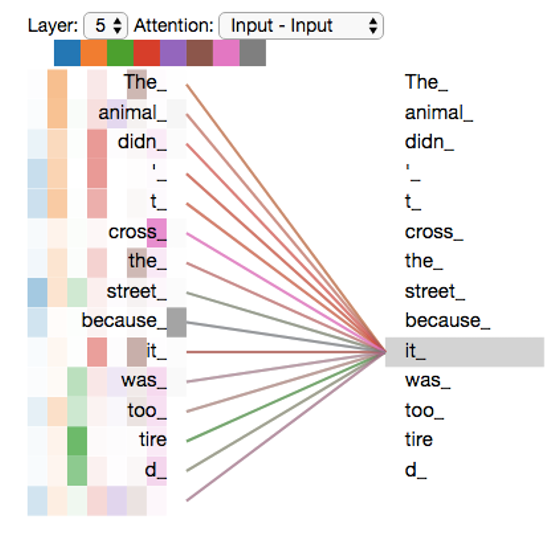
“The animal didn’t cross the street because it was too tired”

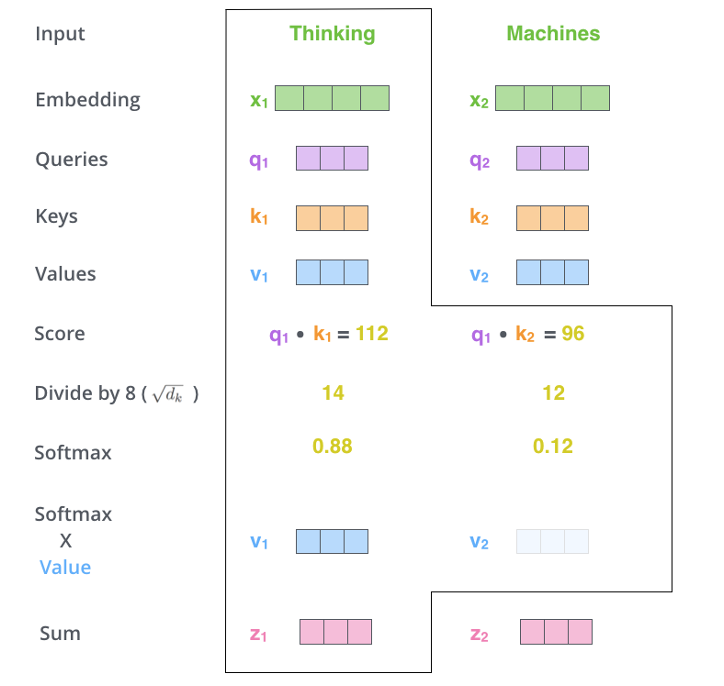
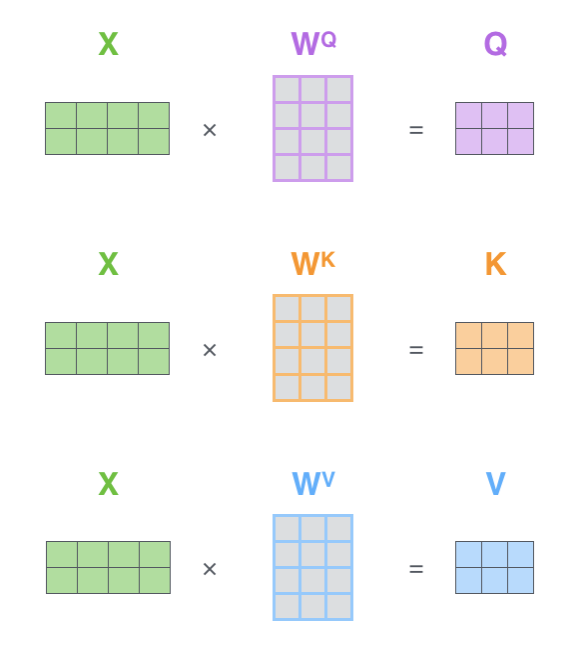


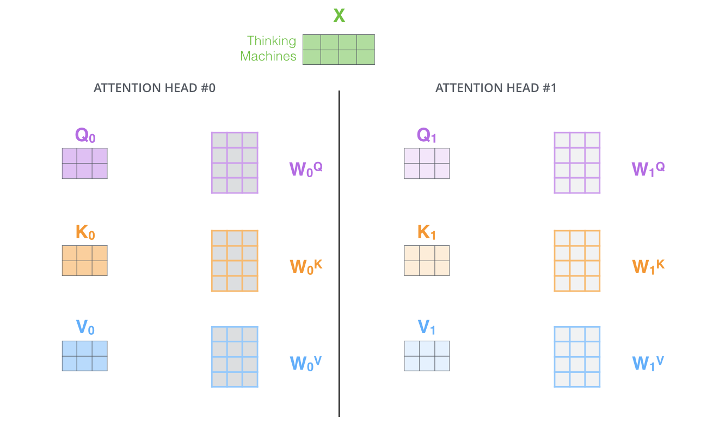
Transformer – Self Attention – Multiheads

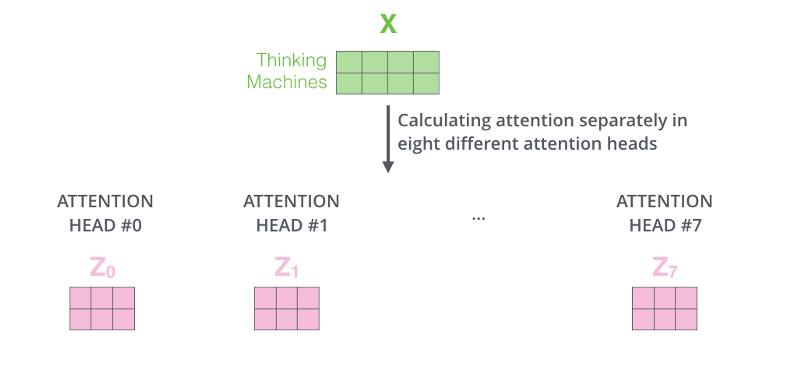
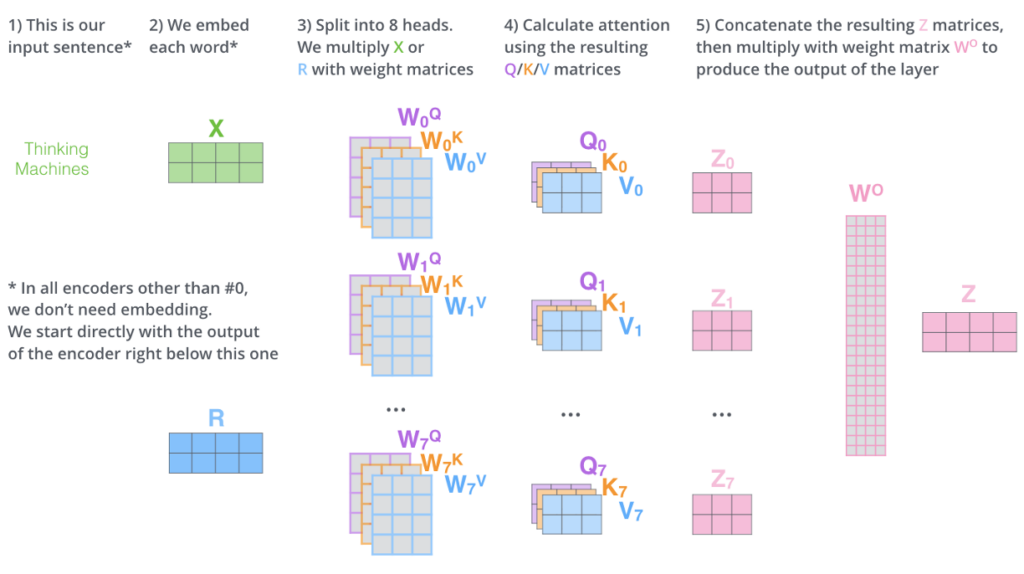
Positional Encoding
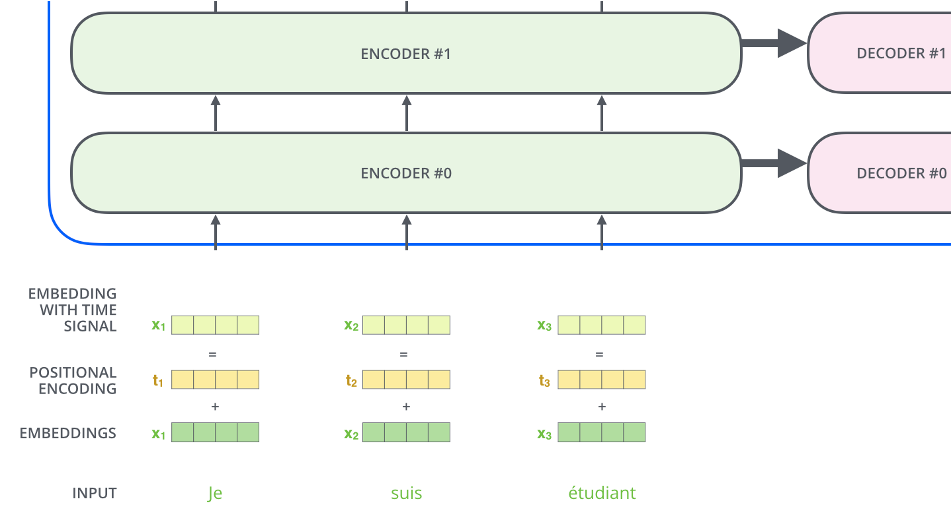
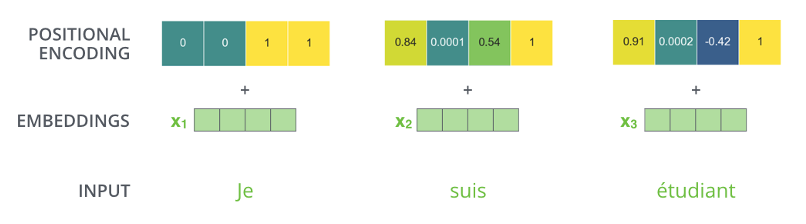
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
target_vocab_size, pe_input, pe_target, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff,
input_vocab_size, pe_input, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff,
target_vocab_size, pe_target, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask,
look_ahead_mask, dec_padding_mask):
enc_output = self.encoder(x=inp, training=training, mask=enc_padding_mask) # (batch_size, inp_seq_len, d_model)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attention_weights = self.decoder(
x=tar, enc_output=enc_output, training=training, look_ahead_mask=look_ahead_mask, padding_mask=dec_padding_mask)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output, attention_weightsTransformer Visulization
- https://bbycroft.net/llm
- https://poloclub.github.io/transformer-explainer/
- https://colab.research.google.com/drive/1abGqHB2qgEtbV6iAx5fQuaHJHQWN84JA
Future Work
- Sparse Attention Mechanisms | Sparse Attention: Real-time language translation and document summarization with extended context.
- Linear Transformers | Linear Transformers: Time-sensitive applications like live speech-to-text transcription and financial forecasting.
- Dynamic and Selective Sparsity in Transformers | Dynamic Sparsity: Optimizing chatbot response times and adaptive language models for dynamic dialogues.
- Multi-Modal Transformers | Multi-Modal Transformers: Augmented reality systems that process visual and auditory cues simultaneously, enhancing user interaction.
- Energy-Efficient and Hardware-Optimized Transformers | Energy-Efficient Transformers: Practical NLP applications on mobile devices and real-time IoT sensors for environmental monitoring.
Reference
- https://www.kaggle.com/code/ezzzio/transformers-for-dummies
- https://jalammar.github.io/illustrated-transformer/
- https://michielh.medium.com/transformers-unleashed-the-neural-architecture-powering-modern-ai-and-language-models-57626643fd49
- https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
- https://towardsdatascience.com/transformers-141e32e69591
- https://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://medium.com/technology-invention-and-more/how-to-build-a-simple-neural-network-in-9-lines-of-python-code-cc8f23647ca1
- https://machinelearningmastery.com/understanding-simple-recurrent-neural-networks-in-keras/
- https://towardsdatascience.com/illustrated-guide-to-transformers-step-by-step-explanation-f74876522bc0
- https://www.datacamp.com/tutorial/how-transformers-work
- https://medium.com/@amanatulla1606/transformer-architecture-explained-2c49e2257b4c
Leave a Reply